Why Claude's Team Is Ditching Markdown as AI Output Explodes from 10 to 1,000 Lines
- Smars
- Agent Skills , AI Efficiency
- 09 May, 2026
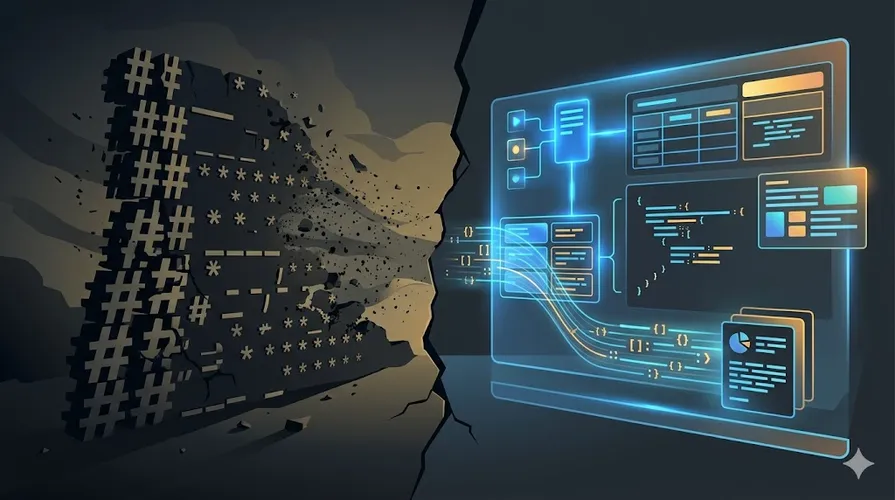
Your AI can now generate 1,000-line plans, complex flowcharts, and full code reviews in one shot. And you are still reading it in Markdown.
Thariq, an engineer on the Claude Code team, recently posted a blunt take on X: the team has completely ditched Markdown. Not because Markdown is bad, but because AI has evolved faster than plain text can keep up. Ten-line notes used to fit Markdown perfectly. Now an agent can spit out an entire operations manual, and a wall of asterisks and hash symbols is simply unreadable.
This is not one engineer’s preference. It is a paradigm shift in how AI output is formatted.
Markdown’s Bottleneck Is Not Syntax, It Is Information Density
Markdown was designed as a lightweight markup language so humans could write formatted documents in plain text. Its core assumptions were: moderate content volume, humans as the primary readers, and reading speed is not the bottleneck.
Those assumptions held in 2023. They do not hold anymore.
A Claude Code skill can contain 500 lines of instructions, multiple reference documents, executable scripts, and templates. Stuffing everything into a single Markdown file means loading the entire text wall into context on every invocation. Anthropic’s internal data tells the story: with progressive disclosure, context usage drops from tens of thousands of tokens for a full load to roughly 10-30 tokens of metadata per skill, with actual content read on demand.
An even sharper example comes from a Claude Code GitHub issue: when a model draws a table using box-drawing characters, a 6-row, 4-column table costs about 1,800 characters. The same content in Markdown table syntax is about 600 characters, a 3x difference. Every corner and line character is its own token, and the model must pre-compute column widths and alignment, pure compute waste for an autoregressive model.
Markdown is not saving tokens. It is becoming a token black hole.
Progressive Disclosure: Only Load What You Need Right Now
The Claude Code skills system offers a compelling alternative. A skill is not a single Markdown file. It is a folder:
- SKILL.md: entry-point instructions (loaded on invocation)
- references/: detailed docs (read on demand)
- scripts/: executable scripts (loaded at runtime)
- templates/: template files (read when needed)
This pattern is called progressive disclosure. At startup the system loads only each skill’s name and description (about 10-30 tokens). The full body is pulled into context only when the skill is actually called. Anthropic’s numbers show the impact: traditional full loading of an MCP tool library burns 77,000 tokens. With on-demand tool discovery, that drops to 8,700 tokens, an 85% reduction. Cursor’s dynamic context discovery achieved a 46.9% token cut. CloudFlare replaced MCP schemas with TypeScript sandboxes and slashed token usage by 98.7%.
Three top-tier companies independently arrived at the same conclusion: do not preload all tool descriptions into context. Let the agent discover what it needs.
This principle applies directly to AI output. Rather than having the model vomit a 1,000-line Markdown document, have it return a structured summary and let the user expand only the sections they care about.
Structured Output Is Replacing Free-Form Text
The more direct trend: structured output is eliminating Markdown’s necessity at the API layer.
Anthropic’s Claude API supports output_config.format. OpenAI has response_format with strict: true. Gemini offers response_schema. They all do the same thing: force the model to return data that strictly conforms to a schema, not free-form text.
What does this mean? Instead of the model outputting ”## Step 1\n\nOpen the file…” as a Markdown paragraph, it returns raw JSON:
{
"steps": [
{"id": 1, "action": "open_file", "target": "config.yaml"},
{"id": 2, "action": "edit", "field": "compression.threshold", "value": 0.8}
]
}The client receives this JSON and can render it as a table, a timeline, a clickable card, whatever makes sense. Content and presentation are fully decoupled. The model produces data. The UI layer handles making it human-readable.
LangChain, OpenAI Agents SDK, and AgentsKit are all pushing the same pattern: agents return typed JSON, and the frontend maps it to purpose-built UI components. Tables render as tables. Code gets syntax highlighting. Status updates become cards. The model no longer has to typeset its own output.
When to Upgrade Your Output Format
Not every scenario needs to abandon Markdown. Three situations are worth serious consideration:
- Complex outputs from AI coding agents: Tools like Claude Code, Cursor, and Codex frequently need to emit multi-file plans, dependency graphs, and test strategies. Markdown is token-expensive and hard to scan for this volume.
- Intermediate states in multi-step workflows: When an agent runs 10+ steps, structured JSON status updates are more context-efficient than Markdown paragraphs, and easier for downstream tools to parse.
- Human-in-the-loop review scenarios: Code reviews, document audits, data analysis reports. Collapsible cards, lists with status badges, and clickable expand regions are far easier to focus on than a raw Markdown wall.
Conversely, two scenarios where Markdown still suffices:
- One-off short answers: If it can be said in three to five sentences, structured output is overkill.
- Human-facing long-form prose: Blogs, manuals, emails where the intended reader is a human, not a downstream system. Markdown’s portability remains an advantage here.
Pitfalls: Structured Output Is Not a Panacea
Migrating to structured output has several common traps:
Schema design cost. Good structured output requires upfront schema definition, which is significantly more work than writing “output in Markdown” in a prompt. Changing the schema once means touching both frontend and backend. For small teams with only one or two people maintaining prompts, the overhead may not be worth it.
Streaming complexity. Structured output is painful in streaming scenarios. A JSON object halfway through generation produces an incomplete syntax tree on the frontend, which flashes and shifts. You need to buffer block-level elements (tables, code fences) until complete, then stream paragraph text progressively. This is an order of magnitude more complex than streaming raw Markdown.
Model drift. OpenAI’s documentation admits that with prompt-level format instructions alone, complex schema conformance is only 85-90%. To reach 99%+, you need API-level constrained decoding (JSON mode, strict tool use). This means you cannot just write “please output JSON” in the prompt. You must change how you call the API.
Over-structuring. Not all content fits tables and cards. Emotional expression, creative writing, and open-ended discussion become rigid and lifeless when forced into a schema. Structure is a tool, not a religion.
Quick Start: Migrating from Markdown to Mixed Output
You do not need to abandon Markdown all at once. A pragmatic migration path:
Step 1: Separate content from presentation
Tell the model in the system prompt: you only output raw data. Formatting is handled by the client. Stop asking the model to draw tables and align columns itself.
Step 2: Use JSON for complex output, keep Markdown for simple output
The decision rule: if this output might be parsed by downstream code, use JSON. If it is purely for human consumption, Markdown is fine. A hybrid strategy is the most realistic.
Step 3: Introduce progressive disclosure
Split long documents into an entry-point summary plus on-demand detailed sections. Claude Code’s skill folder structure can be reused directly: one main file for the overview, subdirectories for detailed references that are read only when needed.
Step 4: Add a client-side rendering layer
This is the critical step. Models output Markdown tables because clients cannot render JSON. Give your frontend a responsive rendering pipeline that supports multiple block types: text, markdown, card, code, and action.
Closing
Markdown is not going away. It is still the most convenient way for humans to write documents. But when AI output grows from 10 lines to 1,000 lines, and when the consumer shifts from humans to systems, a plain text wall stops being the answer.
The real signal in Claude’s team ditching Markdown is not a format war. It is a deeper transformation: AI output is shifting from “text for humans to read” to “data for systems to consume.” This means content and presentation must separate. Progressive disclosure must become the default architecture. Structured output must replace free-form text.
Your AI is already generating 1,000-line plans. Is your reading workflow keeping up?
Sources:
- Original X post: https://x.com/AYi_AInotes/status/2052842474687680678
- Claude Code Skills docs: https://docs.anthropic.com/en/docs/claude-code/skills
- Progressive Disclosure analysis: https://www.developersdigest.tech/blog/progressive-disclosure-claude-code
- Claude Code GitHub Issue #45111: https://github.com/anthropics/claude-code/issues/45111