当 AI 输出从 10 行暴涨到 1000 行,Claude 团队为什么正在抛弃 Markdown
- Smars
- Agent skill , AI 效率
- 09 May, 2026
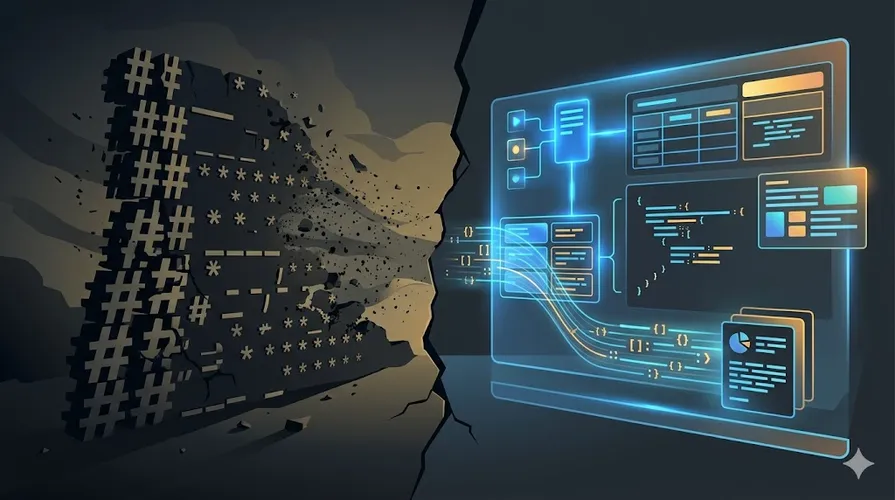
你的 AI 能一次性输出 1000 行计划、画复杂流程图、做完整代码审查。但你还在用 Markdown 读它。
Claude Code 团队工程师 Thariq 最近在 X 上发了一条很直接的推文:团队已经彻底抛弃 Markdown 了。不是 Markdown 不好用,是 AI 变得太快,纯文字墙已经跟不上了。以前 AI 写 10 行笔记,Markdown 刚刚好。现在 AI 能吐出整本操作手册,密密麻麻的星号和井号,谁有耐心看得完?
这不是某个工程师的偏好问题。这是 AI 输出格式正在经历的一次范式转移。
Markdown 的瓶颈不是语法,是信息密度
Markdown 的设计初衷是轻量级标记——让人类用纯文本写出带格式的文档。它的核心假设是:内容量适中、人类是主要读者、阅读速度不是瓶颈。
这些假设在 2023 年还成立。现在全碎了。
Claude Code 的一个 skill 可以包含 500 行指令、多个参考文档、可执行脚本和模板。如果把所有内容都塞进一个 Markdown 文件里,每次加载都要把整块文本推进上下文窗口。Anthropic 内部的数据很能说明问题:skills 采用 progressive disclosure(渐进式披露)后,上下文占用从完整加载的数十万字降到仅 10-30 个 token 的元数据描述,调用时才按需读取具体内容。
另一个更直观的例子来自 Claude Code 的 GitHub issue:模型用 box-drawing 字符画表格时,一个 6 行 4 列的表格要消耗约 1800 个字符。同样的内容用 Markdown 表格语法只要约 600 个字符,差了三倍。每个角线、横线都是独立 token,模型还要预先计算所有列宽和对齐——这对自回归模型来说是纯粹的算力浪费。
Markdown 不是在节省 token,它正在成为 token 黑洞。
Progressive Disclosure:只加载你现在需要看的
Claude Code 的 skills 系统给了一个很好的替代思路。一个 skill 不是单个 Markdown 文件,而是一个文件夹:
- SKILL.md:入口说明(加载时只读这部分)
- references/:详细参考文档(按需读取)
- scripts/:可执行脚本(运行时才加载)
- templates/:模板文件(用到时才读)
这种模式的核心叫 progressive disclosure。系统在启动时只加载每个 skill 的名称和描述(约 10-30 token),真正调用 skill 时才把完整内容拉进上下文。Anthropic 的数据显示,传统方式加载完整 MCP 工具库要消耗 77,000 token,用 tool search 按需发现降到 8,700 token,省了 85%。Cursor 的动态上下文发现也实现了 46.9% 的 token 削减。CloudFlare 用 TypeScript sandbox 替代 MCP schema,更是砍掉了 98.7% 的 token 用量。
三家头部公司独立 arrive 到同一个结论:不要把所有工具说明塞进上下文,让 agent 自己发现需要什么。
这个原则完全可以复用到 AI 输出上。与其让模型一次性吐出 1000 行 Markdown 文档,不如让它返回一个结构化摘要,用户点哪里才展开哪里。
结构化输出正在取代自由文本
另一个趋势更直接:结构化输出(structured output)正在从 API 层消灭 Markdown 的必要性。
Anthropic 的 Claude API 支持 output_config.format,OpenAI 有 response_format 配 strict: true,Gemini 有 response_schema。它们共同做一件事:让模型返回严格符合 schema 的数据,而不是自由格式的文本。
这意味着什么?模型不再输出 ”## 步骤 1\n\n打开文件…” 这种 Markdown 段落,而是直接返回 JSON:
{
"steps": [
{"id": 1, "action": "open_file", "target": "config.yaml"},
{"id": 2, "action": "edit", "field": "compression.threshold", "value": 0.8}
]
}客户端拿到这个 JSON,想渲染成表格、时间线、可点击的卡片,都可以。内容跟表现彻底分离。模型只负责产生数据,UI 层负责把数据变成人类可读的形式。
LangChain、OpenAI Agents SDK、AgentsKit 都在推同一个模式:agent 返回 typed JSON,前端映射到对应 UI 组件。表格用表格渲染,代码用语法高亮,状态更新用卡片。不再需要模型自己排版。
适用场景:什么时候该升级你的输出格式
不是所有场景都需要抛弃 Markdown。三种情况值得认真考虑:
- AI 编程 agent 的复杂输出:Claude Code、Cursor、Codex 这类工具经常要输出多文件计划、依赖关系图、测试策略。用 Markdown 写这些内容,token 开销大、可读性差。
- 多步骤工作流的中间状态:agent 执行 10 步以上的任务时,每步的状态更新用结构化 JSON 比用 Markdown 段落更省上下文,也更容易被下游工具解析。
- 需要人机协作的审查场景:代码审查、文档评审、数据分析报告。用可折叠的卡片、带状态标记的列表、可点击的展开区域,比纯 Markdown 墙更容易让人集中注意力。
反过来,两种场景 Markdown 仍然够用:
- 一次性简短回答:三五句话能说清楚的,没必要上结构化输出。
- 人类直接阅读的长文:博客、说明书、邮件,目标读者是人类而非下游系统,Markdown 的通用性仍然是优势。
踩坑:结构化输出不是万能药
迁移到结构化输出有几个常见的坑:
Schema 设计成本。好的结构化输出需要预先定义 schema,这比写一句 “用 Markdown 输出” 要麻烦得多。schema 改一次,前后端都要动。小团队如果只有一两个人维护 prompt,维护 schema 的 overhead 可能不划算。
流式渲染的复杂度。结构化输出在流式场景下很麻烦。JSON 对象生成到一半时,前端收到的是不完整的语法树,渲染出来会闪、会错位。需要缓冲块级元素(表格、代码块)直到完整,再渐进渲染文本段落。这比直接流式输出 Markdown 要复杂一个数量级。
模型漂移。OpenAI 的文档承认,仅靠 prompt 里的格式指令,复杂 schema 的 conformance 只有 85-90%。要达到 99%+ 必须用 API 层的 constrained decoding(JSON mode、strict tool use)。这意味着你不能只在 prompt 里写 “请输出 JSON”,必须改 API 调用方式。
过度结构化。不是所有内容都适合表格和卡片。情感化表达、创意写作、开放式讨论,强行塞进 schema 只会让输出变僵硬。结构是工具,不是 religion。
快速上手:从 Markdown 迁移到混合输出
你不需要一次性抛弃 Markdown。一个务实的迁移路径:
第一步:分离内容与表现
在 system prompt 里明确告诉模型:你只负责输出原始数据,格式由客户端处理。不要再让模型自己画表格、排列表格。
第二步:对复杂输出用 JSON,对简单输出保留 Markdown
判断标准:如果这段输出可能被下游代码解析,用 JSON;如果只是给人类读,用 Markdown。混合策略是最现实的。
第三步:引入 progressive disclosure
把长文档拆成入口摘要 + 按需加载的详细内容。Claude Code 的 skill 文件夹结构可以直接复用:一个主文件放概述,子目录放详细资料,用到时才读取。
第四步:客户端加渲染层
这是最关键的一步。模型输出 Markdown 表格是因为客户端没能力渲染 JSON。给前端加一个响应式渲染管道,支持 text、markdown、card、code、action 等多种 block 类型。
结尾
Markdown 不会消失。它仍然是人类写文档最方便的方式。但当 AI 的输出从 10 行变成 1000 行,从给人看变成给系统解析,纯文本墙就不再是答案了。
Claude 团队抛弃 Markdown 的真正信号不是格式之争,而是一个更底层的转变:AI 的输出正在从 “让人读的文字” 变成 “让系统消费的数据”。这个转变意味着内容跟表现必须分离,意味着 progressive disclosure 必须成为默认架构,意味着结构化输出必须取代自由文本。
你的 AI 已经在输出 1000 行计划了。你的阅读方式还跟得上吗?
来源:
- X 原文: https://x.com/AYi_AInotes/status/2052842474687680678
- Claude Code Skills 文档: https://docs.anthropic.com/en/docs/claude-code/skills
- Progressive Disclosure 分析: https://www.developersdigest.tech/blog/progressive-disclosure-claude-code
- Claude Code GitHub Issue #45111: https://github.com/anthropics/claude-code/issues/45111