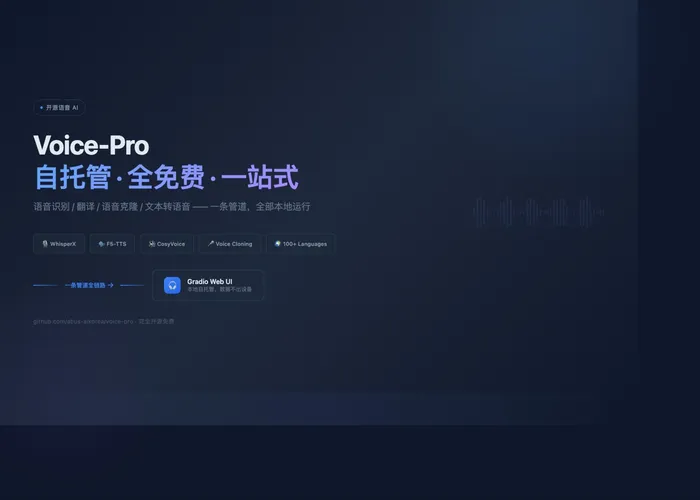
Voice-Pro Is Now Open-Source: A Self-Hosted ElevenLabs Alternative
Most voice AI tools either charge by the minute (ElevenLabs, Maestra) or force you to juggle separate tools for speech-to-text, TTS, and translation. Voice-Pro is a self-hosted Gradio application that bundles YouTube downloading, audio separation, speech recognition, translation, voice cloning, and text-to-speech into a single web UI. As of v3.2, every line of code is open-source and free.
One pipeline, full coverage
Drop in a YouTube link or a local video file. yt-dlp handles the download, Demucs separates vocals from background, Whisper (or Faster-Whisper, WhisperX) generates transcripts, Deep-Translator translates into 100+ languages in real time, and the final speech comes from Edge-TTS, F5-TTS, CosyVoice, or kokoro — all supporting zero-shot voice cloning from a 30-second sample. Every model runs locally; your data never touches a third-party server.
The math against commercial SaaS
To process a 60-minute video for subtitles, translation, and dubbing: Maestra runs ~$24, Kapwing $30–40, HappyScribe $36–48. Voice-Pro costs zero. But the real advantage isn’t the price — it’s control. No API price hikes, no privacy risks, no format restrictions. It supports WhisperX word-level highlighting, F5-TTS fine-tuned models for multiple languages, and kokoro, ranked #2 on the HuggingFace TTS Arena. The hardware requirement: one NVIDIA GPU with CUDA 12.4.
The paywall around voice AI is rarely a technology barrier — it’s almost always a distribution decision. Voice-Pro just tore it down.